
训练过程
代码
训练参数
exp_name:实验名称,用于标识不同的实验记录。max_iters:最大迭代次数,即训练数据集将被多少次迭代。log_freq:日志记录频率,每隔多少次迭代记录一次日志文件。shuffle:是否对数据集进行随机打乱。dset:数据集类型,例如训练集、验证集等。do_val:是否进行验证。val_freq:验证频率,每隔多少次迭代进行一次验证。save_freq:保存模型频率,每隔多少次迭代保存一次模型。batch_size:批处理大小。grad_acc:梯度累积步数,即需要多少次反向传播后才更新模型权重。lr:学习率。use_scheduler:是否使用学习率调度器。weight_decay:L2正则化项的权重。nworkers:数据加载器中使用的进程数量。data_dir:数据集存储目录。log_dir:日志存储目录。ckpt_dir:模型检查点存储目录。keep_latest:保存多少个最新的检查点。init_dir:预训练模型路径。ignore_load:是否忽略某些层的权重加载。load_step:是否从指定步数的检查点处恢复训练。load_optimizer:是否从检查点中恢复优化器状态。res_scale:图像分辨率缩放比例。rand_flip:是否进行随机翻转增强。rand_crop_and_resize:是否进行随机裁剪和调整尺寸增强。ncams:使用的摄像头数量。nsweeps:使用的雷达扫描数量。encoder_type:使用的卷积神经网络编码器类型。use_radar:是否使用雷达数据。use_radar_filters:是否使用雷达数据的滤波器。use_lidar:是否使用激光雷达数据。use_metaradar:是否使用元雷达数据。do_rgbcompress:是否进行RGB图像压缩。do_shuffle_cams:是否对不同的摄像头进行混洗增强。device_ids:GPU设备ID列表。
model_name生成
B = batch_size
assert(B % len(device_ids) == 0) # batch size must be divisible by number of gpus
if grad_acc > 1:
print('effective batch size:', B*grad_acc)
device = 'cuda:%d' % device_ids[0]
# autogen a name
model_name = "%d" % B
if grad_acc > 1:
model_name += "x%d" % grad_acc
lrn = "%.1e" % lr # e.g., 5.0e-04
lrn = lrn[0] + lrn[3:5] + lrn[-1] # e.g., 5e-4
model_name += "_%s" % lrn
if use_scheduler:
model_name += "s"
model_name += "_%s" % exp_name
import datetime
model_date = datetime.datetime.now().strftime('%H:%M:%S')
model_name = model_name + '_' + model_date
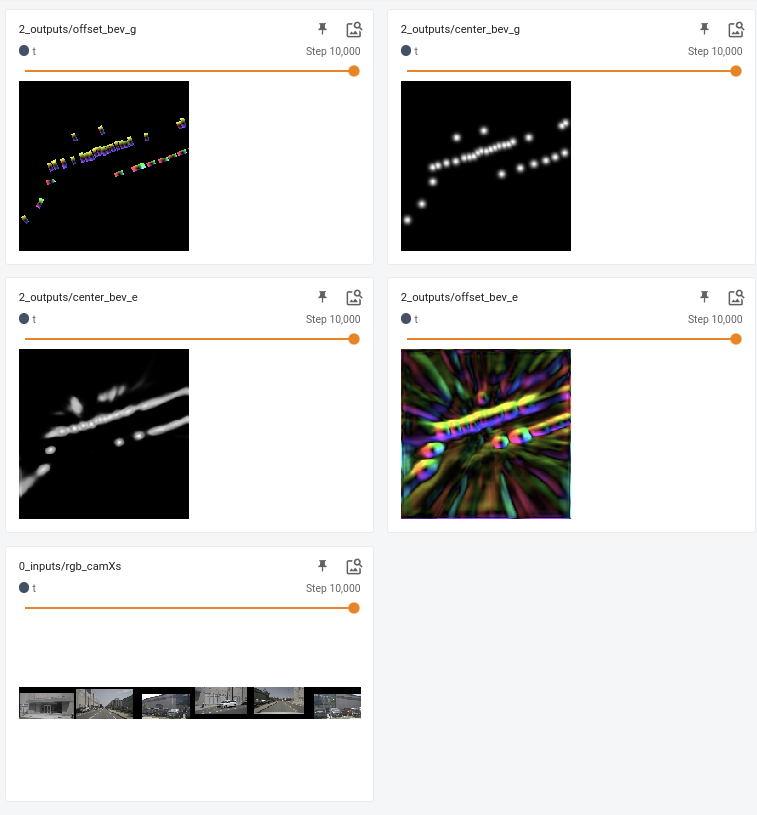
print('model_name', model_name)拿我的实验model_name做比方:
1x5_3e-4s_rgb03_17:45:58
gpu数量x梯度累计步数_学习率_是否使用学习率调度器_实验名称_当前时间
生成中间模型与log可视化路径
# set up ckpt and logging
ckpt_dir = os.path.join(ckpt_dir, model_name)
writer_t = SummaryWriter(os.path.join(log_dir, model_name + '/t'), max_queue=10, flush_secs=60)
if do_val:
writer_v = SummaryWriter(os.path.join(log_dir, model_name + '/v'), max_queue=10, flush_secs=60)根据model_name生成中间模型路径ckpt_dir与训练结果t和验证结果v到tensorboard中
数据增强参数生成
# set up dataloaders
final_dim = (int(224 * res_scale), int(400 * res_scale))
print('resolution:', final_dim)
if rand_crop_and_resize:
resize_lim = [0.8,1.2]
crop_offset = int(final_dim[0]*(1-resize_lim[0]))
else:
resize_lim = [1.0,1.0]
crop_offset = 0
data_aug_conf = {
'crop_offset': crop_offset,
'resize_lim': resize_lim,
'final_dim': final_dim,
'H': 900, 'W': 1600,
'cams': ['CAM_FRONT_LEFT', 'CAM_FRONT', 'CAM_FRONT_RIGHT',
'CAM_BACK_LEFT', 'CAM_BACK', 'CAM_BACK_RIGHT'],
'ncams': ncams,
}生成data_aug_conf后面用于dataloader。
其中,224 和 400 是用于计算 final_dim 的尺寸大小,表示最终图像应该在高和宽方向上分别缩放到多少像素。而 900 和 1600 则是原始图像的高度和宽度,它们可以用来计算图像在裁剪时的位置,以及对图像进行缩放时需要保留的比例。
数据解析函数参数
version:数据集的版本号或特定配置的标识。dataroot:数据集存储的根目录路径。data_aug_conf:数据增强的配置,用于在训练过程中对数据进行扩充或变换。centroid:数据中心点的位置,通常用于裁剪或缩放数据。bounds:数据边界的范围,用于限制数据的有效区域。res_3d:三维数据的空间分辨率或精度。bsz:训练时使用的批量大小(batch size),表示每次迭代训练时使用的样本数量。nworkers:数据加载时的工作进程数,用于并行加载数据以提高效率。shuffle:是否在训练数据加载时对数据进行洗牌(随机排序)。nsweeps:每个样本的扫描次数,用于模拟多个扫描周期的数据。nworkers_val:验证数据加载时的工作进程数,用于并行加载验证数据以提高效率。seqlen:训练数据序列的长度,用于定义时间序列数据的时间步数。refcam_id:参考相机的 ID,用于标识需要参考的相机。get_tids:是否返回目标 ID 的标志,用于获取目标的标识符。temporal_aug:是否进行时间上的数据增强,用于对时间序列数据进行随机扩充或变换。use_radar_filters:是否使用雷达数据过滤器的标志,用于对雷达数据进行预处理和滤波。do_shuffle_cams:是否在加载数据时对相机进行洗牌(随机排序)。
通过torch.utils.data.Dataset的子类class NuScenes读取nuscenes数据(compile_data)
class NuScenes:
"""
Database class for nuScenes to help query and retrieve information from the database.
"""
def __init__(self,
version: str = 'v1.0-mini',
dataroot: str = '/home/sczone/01_workspace/04_model/bevfusion/data/nuscenes',
verbose: bool = True,
map_resolution: float = 0.1):加载NuScenes数据库,并创建反向索引和快捷方式,以便查询和检索数据库中的信息。初始化了一些地图分辨率、表名等。加载lidar分割数据(如果有)和图像注释数据(如果有),初始化map记录的地图掩码。初始化了一个NuScenesExplorer类的实例,该类用于浏览NuScenes数据库并执行高级查询和可视化。
通过NuScenes的子类VizData对数据进行可视化
class VizData(NuscData):
def __init__(self, *args, **kwargs):
super(VizData, self).__init__(*args, **kwargs)
Z, Y, X = self.res_3d
self.vox_util = utils.vox.Vox_util(
Z, Y, X,
scene_centroid=torch.from_numpy(self.centroid).float().cuda(),
bounds=self.bounds,
assert_cube=False)
self.Z, self.Y, self.X = Z, Y, X根据数据的三维分辨率(Z、Y、X)创建一个Vox_util对象,该对象用于将数据转换为体素表示,并提供一些体素操作的工具函数。它还使用场景的质心(centroid)和边界(bounds)初始化Vox_util对象。其中self.centroid表示场景的质心,它是一个包含三个坐标值(X、Y、Z)的numpy数组。通过将其转换为PyTorch张量并放置在GPU上,可以在处理和计算场景数据时获得更高的计算性能。
体素初始化
class Vox_util(object):
def __init__(self, Z, Y, X, scene_centroid, bounds, pad=None, assert_cube=False):
self.XMIN, self.XMAX, self.YMIN, self.YMAX, self.ZMIN, self.ZMAX = bounds
B, D = list(scene_centroid.shape)
self.Z, self.Y, self.X = Z, Y, X
scene_centroid = scene_centroid.detach().cpu().numpy()
x_centroid, y_centroid, z_centroid = scene_centroid[0]
self.XMIN += x_centroid
self.XMAX += x_centroid
self.YMIN += y_centroid
self.YMAX += y_centroid
self.ZMIN += z_centroid
self.ZMAX += z_centroid
self.default_vox_size_X = (self.XMAX-self.XMIN)/float(X)
self.default_vox_size_Y = (self.YMAX-self.YMIN)/float(Y)
self.default_vox_size_Z = (self.ZMAX-self.ZMIN)/float(Z)用于设置体素表示的相关参数,并根据这些参数计算体素的大小和边界。接受传入的Z、Y、X分别表示体素在Z、Y、X三个方向上的数量(分辨率)。从scene_centroid参数中取出场景的质心坐标,并根据这些坐标对边界进行调整。通过加上质心坐标,将边界转换为以质心为中心的坐标。 使用边界的范围除以体素的数量来计算每个体素在各个方向上的大小。
通过DataLoader读取上述已经被封装成带有可视化功能的VizData
trainloader = torch.utils.data.DataLoader(
traindata,
batch_size=bsz,
shuffle=shuffle,
num_workers=nworkers,
drop_last=True,
worker_init_fn=worker_rnd_init,
pin_memory=False)
valloader = torch.utils.data.DataLoader(
valdata,
batch_size=bsz,
shuffle=shuffle,
num_workers=nworkers_val,
drop_last=True,
pin_memory=False)将数据iter化
train_iterloader = iter(train_dataloader)
val_iterloader = iter(val_dataloader)当调用iter()方法并传入一个DataLoader对象时,它会返回一个迭代器对象,该迭代器对象可以用于遍历数据集中的批次数据。每次迭代将返回一个包含一个批次数据的张量或其他类型的对象。
TODO:seg_loss_fn
发表回复