
核心类比:一家承接城市地图绘制的建筑公司
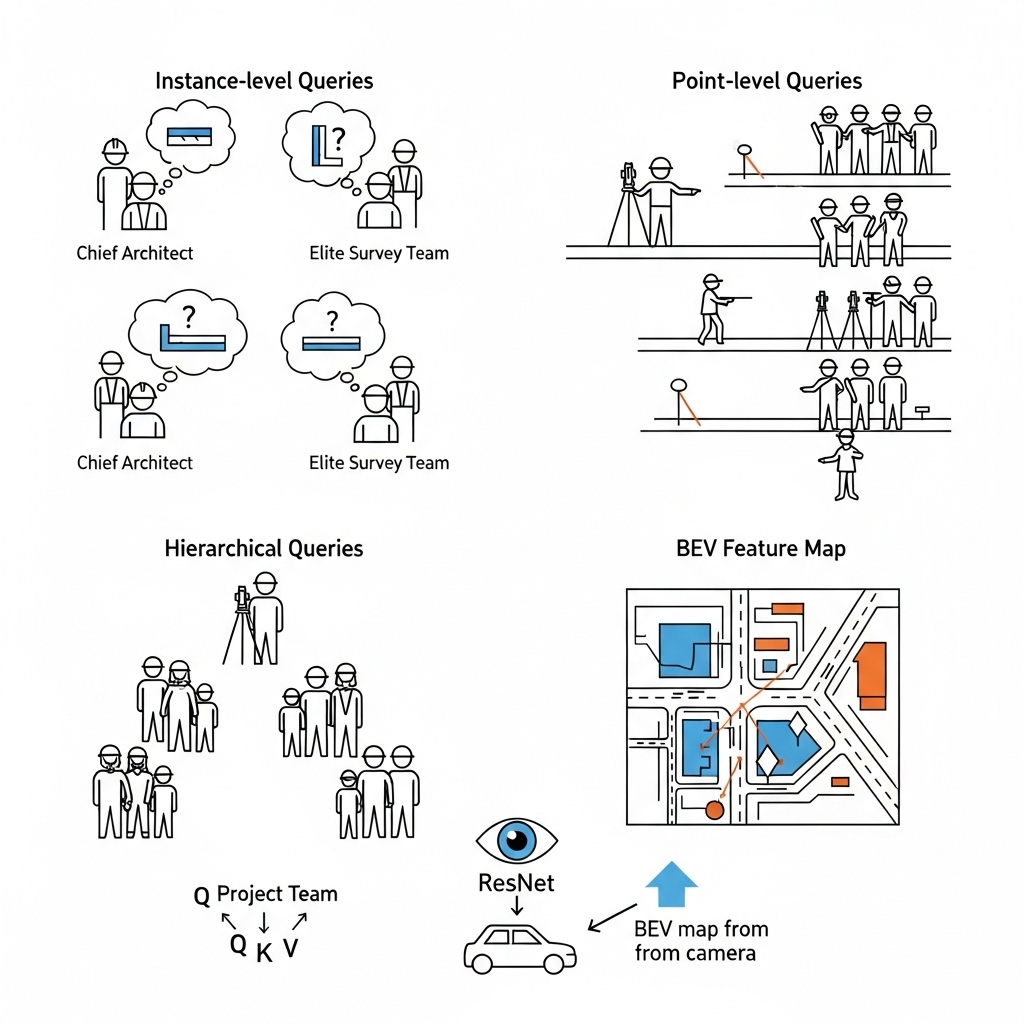
- 实例级查询 (Instance-level Queries) -> 50位“首席建筑师”
- 职责: 每位建筑师负责一个潜在的地图元素(如一条完整的车道线)。他的任务是确定项目的整体定位和类型(“我要建的是什么,大概在哪儿”)。
- 点级查询 (Point-level Queries) -> 一支20人的“精英测量小组”
- 职责: 这个小组是标准化的专家团队,每位成员都擅长定位项目中一个特定的点(如起点、中点、转折点等)。他们是共享资源,提供“如何精确描绘形状”的专业技能。
- 分层查询 (Hierarchical Queries) -> 组建50个“项目团队”
- 过程: 在开工前,公司为每一位建筑师都完整地配备了一支测量小组。通过将建筑师和测量员的信息相加,形成了50个项目团队,共计1000名“专业人员”(
50 * 20个分层查询)。每个团队的目标都非常明确:负责绘制一个特定地图元素的精确形状。
- 过程: 在开工前,公司为每一位建筑师都完整地配备了一支测量小组。通过将建筑师和测量员的信息相加,形成了50个项目团队,共计1000名“专业人员”(
- BEV特征图 (BEV Feature Map) -> 施工现场的“地形勘探图”
- 来源: 由车载摄像头的图像,经过ResNet (眼睛)提取特征,再通过BEV转换模块投影到统一的鸟瞰图视角下,形成的一张富含信息的“地形图”。
- Transformer解码器 -> 项目的“中央协调指挥部”
- 工作: 这里上演着一场盛大的“记者采访会”。
- 提问: 每个项目团队的成员(分层查询)都化身为记者,拿着自己的采访提纲 (Q)。
- 采访: 他们同时向整个“地形图”(BEV特征)进行“采访”。地形图上的每个位置都会亮出自己的名牌 (K) 来表明身份。
- 聆听: 记者通过对比自己的提纲(Q)和所有位置的名牌(K),计算出注意力权重(“哪里与我的问题最相关”)。
- 记录: 根据注意力权重,有选择性地从每个位置的详细稿件 (V) 中提取信息,并聚合成一份精华摘要,用来更新自己。
- 经过多轮“头脑风暴”和信息交换,每个团队成员都对自己的任务有了深刻、全局的理解。
- 工作: 这里上演着一场盛大的“记者采访会”。
- 输出头 (Output Heads) -> “成果翻译与交付部”
- 职责: 将指挥部里高度抽象的“会议纪要”(最终的查询向量)翻译成客户能看懂的成果。
- 分类翻译官: 通过聚合一个项目团队所有成员的信息,判断出这位建筑师负责的项目类别(如“车道线”)。
- 坐标翻译官: 逐一解析团队里每一位测量员的最终报告,输出他们负责的那个点的精确(x, y)坐标。
维度计算全流程展示 (以d_model=256为例)
- 输入:
q_instance:[50, 256]q_point:[20, 256]BEV Features:[H, W, 256]-> 展平后为[N, 256](其中N = H * W)
- 分层查询组合:
- 通过广播机制相加,得到
q_hie:[50, 20, 256]-> 展平后为[1000, 256]
- 通过广播机制相加,得到
- Transformer解码器中的注意力计算 (Attention Layer):
q_hie([1000, 256]) 送入 Q网络 (权重W_Q为[256, 256]) ->Q:[1000, 256]BEV Features([N, 256]) 送入 K网络 (权重W_K为[256, 256]) ->K:[N, 256]BEV Features([N, 256]) 送入 V网络 (权重W_V为[256, 256]) ->V:[N, 256]- 计算注意力权重:
Q([1000, 256]) 与K的转置 ([256, N]) 相乘 ->Attention Scores:[1000, N] - 聚合信息:
Attention Scores([1000, N]) 与V([N, 256]) 相乘 ->Updated Queries:[1000, 256]
- 输出头 (Output Heads):
- 输入: 最终的
q_hie_final:[1000, 256]-> 重塑为[50, 20, 256] - 分类头:
- 聚合操作 (如对20个点取平均):
[50, 20, 256]->q_agg:[50, 256] - 送入分类FFN (权重
W_cls为[256, num_classes]) ->Class Probs:[50, num_classes]
- 聚合操作 (如对20个点取平均):
- 回归头:
- 将
q_hie_final([50, 20, 256]) 直接送入回归FFN (权重W_reg为[256, 2]) ->Coordinates:[50, 20, 2]
- 将
- 输入: 最终的
关于ResNet和特征图大小
“ResNet理论上特征图越大,它能看得越清楚,特征图越小看得就越不清楚,比较模糊,在这篇论文中我们使用了多大的特征图大小?”
您的理论完全正确!特征图的分辨率直接影响模型对细节的感知能力。
在论文附录A的Model Setting部分,他们给出了答案:
- 原始输入图像大小:
1600 x 900 - MapTR-tiny的图像缩放比例:
0.5-> 输入图像变为800 x 450 - MapTR-nano的图像缩放比例:
0.2-> 输入图像变为320 x 180 - BEV网格大小 (size of each BEV grid):
- MapTR-tiny:
0.3m - MapTR-nano:
0.75m
- MapTR-tiny:
这里的BEV网格大小是关键。ResNet输出的特征图最终会被投影到这个BEV网格上。
- 对于MapTR-tiny,
0.3m意味着鸟瞰图中的每个“像素”代表了真实世界中0.3米 x 0.3米的区域。这已经是一个比较高的分辨率了,能看得比较清楚。 - 对于MapTR-nano,
0.75m的分辨率就低了很多,每个像素代表的区域更大,细节自然会更模糊。这也是它速度更快但精度稍低的原因之一。
虽然论文没有直接给出BEV特征图的像素维度(比如200x100),但我们可以根据感知范围和网格大小推断出来。nuScenes数据集的感知范围通常是前后-50m到50m(Y轴),左右-50m到50m(X轴)。如果以一个简化的60m x 30m范围为例:
- MapTR-tiny的BEV特征图大小: 大约是
(60/0.3) x (30/0.3)=200 x 100像素。 - MapTR-nano的BEV特征图大小: 大约是
(60/0.75) x (30/0.75)=80 x 40像素。
这清晰地表明了,为了追求速度,nano版本牺牲了BEV特征图的分辨率,使其看得“更模糊”一些。
发表回复